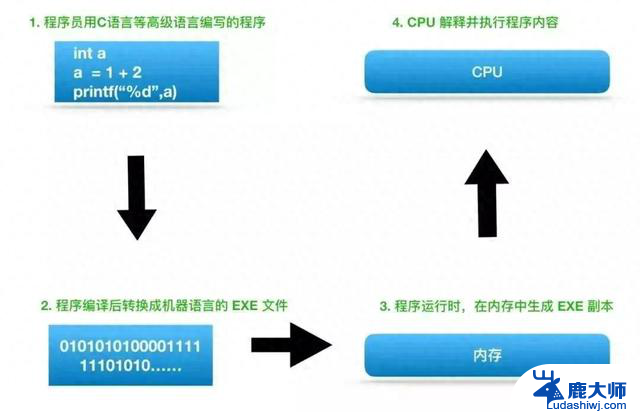
CPU、GPU和NPU区别与作用详解:三者在人工智能计算中的角色分工

前言
理解CPU、GPU和NPU的区别与作用对于把握现代计算设备的核心架构至关重要。它们在设计目标、架构特点和适用场景上各有侧重,相互协作才能满足复杂计算需求。下面我们来详细解析。
一、核心概念与核心区别
(一)CPU (Central Processing Unit - 中央处理器)
1、角色定位:
计算机系统的“大脑”和“总指挥”。它是通用处理器。
2、核心作用:
通用计算: 处理操作系统指令、运行应用程序(办公软件、浏览器、游戏逻辑等)、系统调度和管理。
复杂逻辑控制: 擅长处理需要分支预测、复杂决策、顺序执行的任务(如 if...else 判断、循环)。
串行任务处理: 虽然现代CPU是多核的,但其强项仍然是处理需要按步骤顺序执行的任务。
3、设计特点:
核心数量相对较少(主流桌面CPU通常4-16核)。每个核心非常强大,时钟频率高(GHz级别)。拥有大容量、低延迟的高速缓存。强大的控制单元和复杂的指令集,擅长处理各种不同的任务。强调单线程性能和低延迟。
(二)GPU (Graphics Processing Unit - 图形处理器)
1、角色定位:
专注于大规模并行计算的“加速器”。最初为图形渲染而生,现广泛应用于通用并行计算(GPGPU)。
2、核心作用:
图形渲染: 处理3D模型变换、光照计算、纹理贴图、像素着色等,生成屏幕显示的图像。这是其原始使命。
并行计算: 处理可以分解成大量独立、相对简单的小任务并行执行的计算。典型应用包括:科学计算(物理模拟、分子动力学);人工智能/深度学习(模型训练和推理的核心硬件);视频编解码(H.264, H.265, AV1 等);密码学(挖矿);金融建模。
3、设计特点:
由成千上万个相对简单、节能的小核心(流处理器/CUDA核心/Shader Core)组成。核心时钟频率通常低于CPU。拥有极高的内存带宽(显存带宽远超系统内存带宽)。架构高度优化于同时执行大量相同的操作(SIMD - 单指令多数据)。强调高吞吐量而非单任务的低延迟。
(三)NPU (Neural Processing Unit - 神经网络处理器) / TPU (Tensor Processing Unit - 张量处理器) / AI 加速器
1、角色定位:
专门为人工智能,特别是神经网络计算优化的“专用加速器”。
2、核心作用:
高效执行神经网络运算: 专注于加速深度学习模型(如卷积神经网络CNN、循环神经网络RNN、Transformer等)的推理,有时也参与训练。
核心操作: 极其高效地执行矩阵乘法、卷积运算、激活函数(如ReLU)等神经网络的基本计算操作。
低功耗AI处理: 在移动设备(手机、平板、笔记本)和边缘设备(摄像头、物联网设备)上实现实时、低功耗的AI功能(如拍照增强、语音助手、人脸识别、实时翻译)。
3、设计特点:
高度专用化: 硬件电路直接针对神经网络的核心算子(尤其是矩阵乘加运算MAC)进行优化,通常采用脉动阵列等架构。
极致能效比: 核心设计目标是在尽可能低的功耗下提供尽可能高的AI计算吞吐量,这对移动和嵌入式设备至关重要。
片上内存优化: 非常注重减少数据在计算单元和内存之间的移动,采用近存计算或存内计算技术,因为数据搬运是AI计算的主要能耗来源之一。
量化支持: 通常原生支持INT8、INT4甚至更低精度的运算,显著提升计算效率和降低带宽需求,同时保持可接受的模型精度。
二、关键区别总结
特性
CPU
GPU
NPU (AI加速器)
核心目标
通用计算,控制。低延迟
大规模并行计算,高吞吐量
高效神经网络计算,极致能效比
核心数量
少(几个到几十个)
极多(成千上万个)
数量居中,但高度专用化
核心强度
非常强大,高频率,复杂
相对简单,较低频率
高度定制化,针对特定操作优化
擅长任务
顺序任务,复杂逻辑,操作系统
并行任务,图形渲染,科学计算
神经网络推理/训练(尤其推理)
关键操作
通用指令,分支预测
浮点运算,并行线程处理
矩阵乘法,卷积运算,低精度计算
延迟
低
高
通常较低(针对特定任务)
吞吐量
中等
极高
高(针对AI任务)
能效比
中等
并行任务高,通用任务低
极高(针对AI任务)
主要应用
运行系统/软件,任务调度
游戏,专业图形,HPC,AI训练
设备端AI推理(手机拍照、语音等)
灵活性
最高
高(通过CUDA/OpenCL编程)
最低(专为AI设计)
三、协作关系(现代计算设备)
(一)传统PC/服务器: CPU + GPU
CPU负责运行操作系统、应用程序逻辑、文件I/O、网络通信等通用任务。
当遇到需要大量并行计算的任务(如游戏渲染、视频编码、AI训练)时,CPU将任务卸载(Offload)给GPU执行。GPU完成计算后,将结果返回给CPU。
(二)现代智能手机/AI PC/边缘设备: CPU + GPU + NPU
CPU: 仍然是总指挥,运行操作系统(如Android, iOS, Windows),管理应用生命周期,处理用户交互和通用逻辑。
GPU: 负责图形渲染(UI、游戏画面)、部分通用并行计算任务、以及部分AI计算(尤其是一些GPU友好的模型或操作)。
NPU: 专门高效地处理设备上的AI工作负载。 例如:
手机拍照:NPU实时处理HDR合成、人像虚化、夜景降噪、场景识别。
语音助手:NPU处理语音识别、唤醒词检测。
视频通话:NPU实现背景虚化、美颜效果。
设备端翻译:NPU运行离线翻译模型。
AI PC:NPU加速Windows Studio Effects(背景虚化、眼神接触、自动取景)、Copilot+ AI功能、本地AI应用。
(三)协作流程: 当应用程序需要AI功能(如调用手机相机API进行人像模式拍照):
CPU接收到请求,协调摄像头传感器捕获图像数据。
CPU(或系统调度器)判断最优处理器:对于高度优化的神经网络任务(如人像分割),优先调度给NPU执行,因为其能效比最高。对于更通用或NPU不支持的操作,可能调用GPU或CPU。
NPU高效地执行神经网络推理(如分割出人像区域)。
结果返回给CPU或GPU,GPU利用这个结果进行最终的图像合成和渲染,显示到屏幕上。
CPU全程管理流程和数据流。
四、为什么需要NPU
1、极致能效比: 这是NPU存在的核心价值。在电池供电的移动和边缘设备上,功耗是硬约束。GPU虽然强大且并行能力强,但其通用架构在处理特定AI任务(尤其是推理)时,能效比远低于专门优化的NPU。NPU可以以几分之一甚至几十分之一的功耗完成相同的AI推理任务,显著延长设备续航并减少发热。
2、低延迟: NPU的专用硬件设计可以减少数据搬运和指令译码开销,为实时AI应用(如AR、实时翻译、交互式AI)提供更快的响应速度。
3、专用硬件加速: NPU直接内置针对矩阵乘加等操作的硬件加速单元,效率远超通用处理器。
4、释放CPU/GPU资源: 将耗时的AI任务交给NPU处理,可以让CPU和GPU专注于它们更擅长的任务(如运行应用、渲染图形),提升整体系统流畅度和响应速度。
说在最后
CPU是“全能指挥官”:负责整体协调、逻辑控制和通用计算。GPU是“并行计算巨兽”:擅长处理海量相似数据的并行计算,是图形和高性能计算(包括AI训练)的核心。NPU是“AI特长生”:专为高效执行神经网络计算(尤其是推理)而设计,目标是在设备端实现低功耗、高性能的实时AI体验。三者不是替代关系,而是协同进化、分工合作的关系。随着人工智能应用的爆炸式增长,尤其是设备端AI的需求激增。NPU已经成为现代智能手机、平板电脑、笔记本电脑(AI PC)乃至许多物联网设备中不可或缺的关键组件,与CPU和GPU共同构成了强大的异构计算平台。理解它们的差异和协作方式,有助于更好地理解现代计算设备的工作原理和发展趋势。