AMD MI300X GPU测试,性能远超英伟达H100的最新评测报道
AMD Instinct MI300X 人工智能加速器基于 CDNA 3 架构打造,采用混合的 5nm 和 6nm 制程工艺,最多拥有 1530 亿晶体管。

存储方面也获得了巨大提升,MI300X 的 HBM3 容量比上一代的 MI250X (128 GB) 高出 50%。
与英伟达 H100 相比,MI300X 拥有以下优势:
内存容量高出 2.4 倍
内存带宽高出 1.6 倍
FP8 性能 (TFLOPS) 高出 1.3 倍
FP16 性能 (TFLOPS) 高出 1.3 倍
在 1v1 对比测试中,性能方面可领先 H100 (Llama 2 70B) 最多 20%
在 1v1 对比测试中,性能方面可领先 H100 (FlashAttention 2) 最多 20%
在 8v8 服务器对比测试中,性能方面可领先 H100 (Llama 2 70B) 最多 40%
在 8v8 服务器对比测试中,性能方面可领先 H100 (Bloom 176B) 最多 60%
高速缓存AMD MI300X 配备了 32KB L1 缓存、16KB 标量缓存、4MB L2 缓存和一个巨大的 256MB Infinity Cache(作为 L3 缓存)。
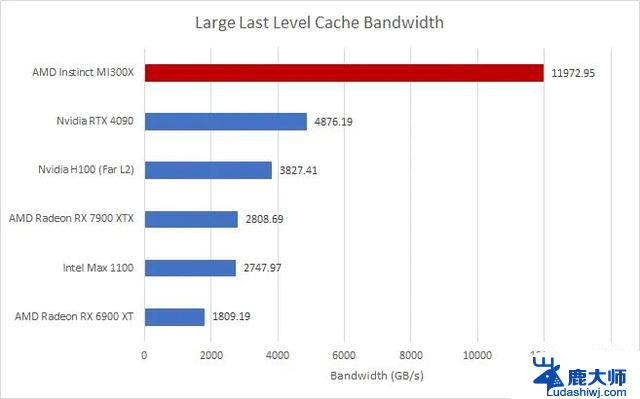
hips and Cheese 的缓存基准测试表明,在所有相关缓存级别中,MI300X 的缓存带宽都大大优于 Nvidia 的 H100。
一级缓存性能显示 MI300X 的带宽是 H100 的 1.6 倍,二级缓存的带宽是 H100 的 3.49 倍,MI300X 的最后一级缓存(即无限缓存)的带宽是 H100 的 3.12 倍。
显存带宽AMD GPU 的本地 HBM3 内存是 H100 PCIe 的 2.72 倍,VRAM 带宽是 H100 PCIe 的 2.66 倍。
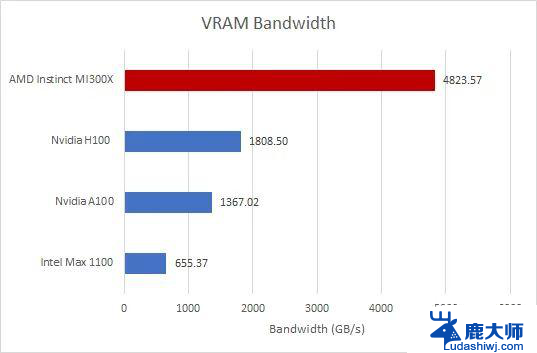
在内存测试中,AMD GPU 唯一失利的地方是内存延迟结果,H100 比 AMD GPU 快 57%。
请注意,这是最低规格的 H100 PCIe 显卡,拥有 80GB HBM2E。后续版本(如 H200)包含高达 141GB 的 HBM3E,带宽最高可达 4.8 TB / s。
Raw 吞吐量Chips and Cheese 的指令吞吐量结果考虑了 INT32、FP32、FP16 和 INT8 计算。
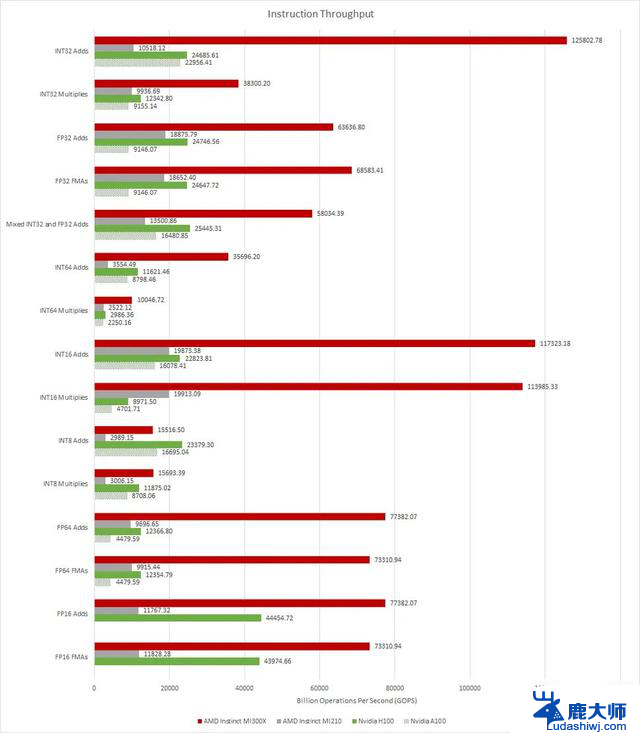
AMD 芯片的指令吞吐量高得离谱。有时,MI300X 比 H100 快 5 倍,最差时也快 40%。
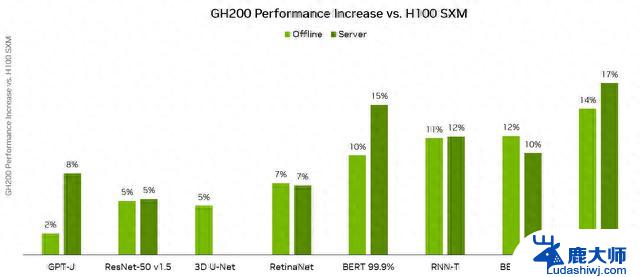
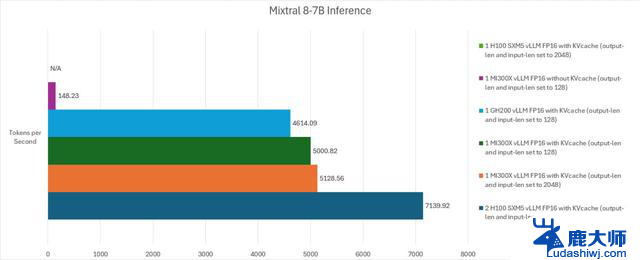
人工智能推理测试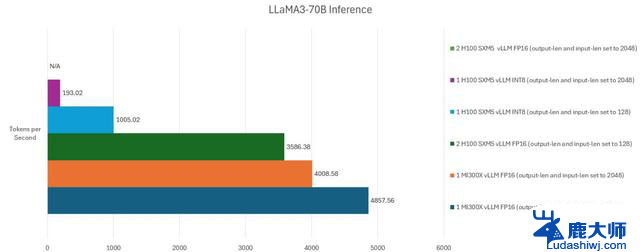
附上原文地址,感兴趣的用户可以深入阅读。