重大进展!国产CPU DCU完美“接盘”Nvidia环境,加速中国自主芯片发展!
近日,有工程师给出一组测试数据。详细展示了客流统计算法从Nvidia环境往国产海光CPU+DCU进行迁移的训练过程,最终结果让人振奋——
基于海光CPU+DCU,在完全采用历史训练代码,不做任何修改的前提下,就能完成整个训练!
该测试以公共场所中的客流信息统计为场景,验证了pytorch和paddlepaddle两种主流的深度学习框架。以及目标检测、行人重识别和多标签分类三种类型的深度学习任务,详细对比了Nvidia GPU和Hygon DCU两种硬件环境下的训练结果。
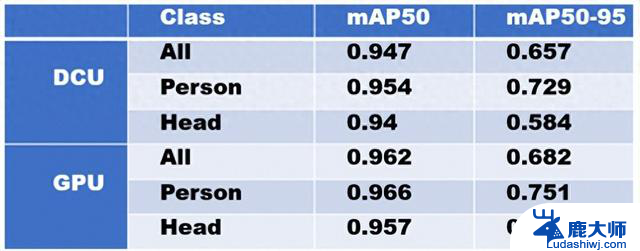
目标检测模型训练数据显示,在训练速度上,海光DCU与Nvidia GPU基本一致,都在平均每秒4次迭代左右(4 it/s);在精度上,根据测试集上的表现,两者相差仅2个百分点;从部分推理结果图来看,DCU和GPU训练出来的模型在推理时表现几乎一样,连预测的置信度都没有差异。
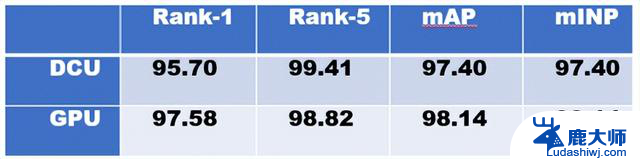
行人重识别模型训练结果显示,在训练速度上,GPU机器平均每次迭代0.65s(0.65s/it),DCU机器平均每次迭代1.34s(1.34s/it),因为采用的是完全相同的训练设置,这里的速度差异应该是由于训练数据加载导致;在精度上,两者在测试集上的数据相差不到2个百分点;识别结果图也基本符合预期。
多标签图像分类模型训练中,海光DCU表现明显更加优异,训练结束后的精度对比中,两者的差异在1个百分点之内;训练速度上,DCU机器和GPU机器差异巨大。其中DCU训练的吞吐量约1410images/sec,GPU训练的吞吐量约194images/sec,在保持精度稳定的基础上,DCU的训练吞吐量堪称惊艳;另外最后的识别结果样例图效果也同样不错。
从总体的使用体验上来看,海光DCU在相同配置环境中,与Nvidia CPU的PK结果远远超出了预期。更难得的是在性能表现达标的基础上,省略了大量修改代码的流程,解决了国内AI厂商最为头疼的适配难题,实现了真正的低成本无痛迁移。